
Introducción
En este post comparto mi experiencia en la creación de un scraper para descargar datos mereológicos. También mostraré unos análisis que hice con los datos y daré unos tips personales para publicar un proyecto open-source.
Empecemos desde el principio. Todo comenzó cuando estaba pensando cómo obtener datos metereológicos para identificar posibles trends. Fue puro interés personal. Vi las opciones online pero no encontré nada satisfactorio. Resulta ser que los datos que suelen publicar para la descarga de distintas organizaciones gubernamentales y no-gubernamentales son muy incompletos o de poca envergadura.
Nada en comparación a la riqueza de datos que tiene wunderground.com. Así que me puse a investigar como descargarlos, sabía que anteriormente era posible. Pero investigando en los foros, aprendí que la descarga ya no estaba disponible. Ahora solo queda la opción de navegar los datos de las miles de estaciones en el mundo. Me sorprendió aprender esto de una página que se sostiene de datos resultantes de crowd-sourcing, es decir de los datos aportados por estaciones personales de la gente.
Si los datos son navegables, pero no descargables, sólo quedaba una opción, crear un scraper. Ya había hecho varios scrapers anteriormente así que me pareció un desafío alcanzable.
Cómo creé al scraper
Hay frameworks que simplifican a la tarea de scraping pero me gusta crear uno propio para adaptarlo a mi necesidad.
Lo primero que hice fue revisar la estructura de la página y de las URLs. Para dar un ejemplo, naveguemos al link de una estación de wunderground.
https://www.wunderground.com/dashboard/pws/IBOQUERO2
Vemos que al hacer click en Table, nos aparece una tabla de datos con mediciones en intérvalos de 5 minutos.
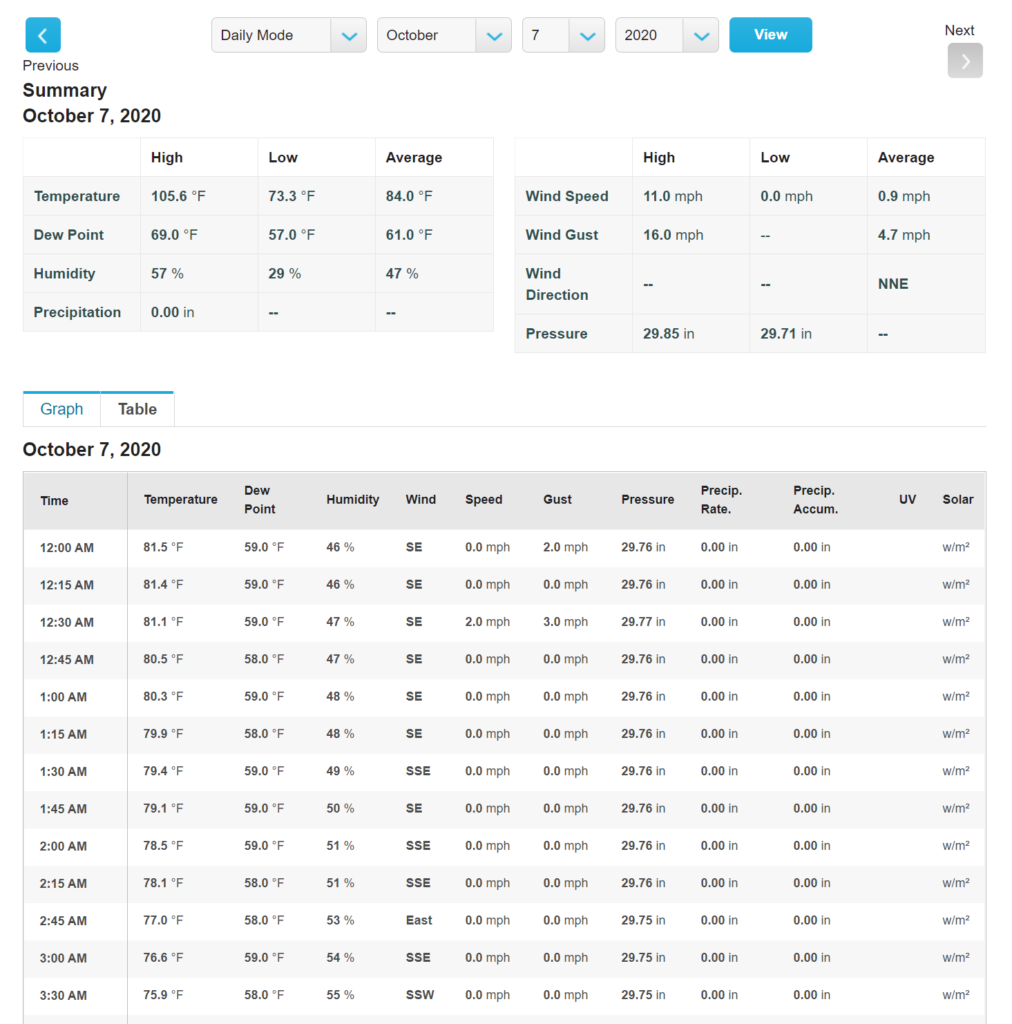
También vemos que la URL ha cambiado y ahora se ve así (dependiendo de la fecha actual) https://www.wunderground.com/dashboard/pws/IBOQUERO2/table/2020-10-7/2020-10-7/daily
Esa última parte me interesa, la url base más la fecha es lo que debemos generar dinámicamente en nuestro scraper. Necesitamos un generador de URLs, y esta vez mi implementación se ve así.
2. Obtener y parsear la tabla de datos
El segundo paso es identificar la ruta de la tabla html. Suelo usar al xpath para eso y Chrome/Firefox tienen funcionalidad para copiarlo desde la consola de desarrollo.
Una vez obtenida la ruta, empecé a jugar en la consola de python hasta poder obtener el contenido de la misma con ayuda de la libreria lxml.
Luego sólo quedaba parsear la tabla html que fue la parte que implicó más trabajo ya que implementé la opción de convertir los datos del sistema imperial de unidades al sistema métrico. No entraré en más detalles del código acá pero dejo el link del repositorio.
https://github.com/Karlheinzniebuhr/the-weather-scraper
También aproveché y implementé una búsqueda binaria para encontrar más rápidamente la primera fecha desde la cual existan datos registrados en cada estación. Fue la primera vez que implementé un algoritmo avanzado para resolver un problema real debido a que hoy en día en la ingeniería de software ya casi todo siempre está resuelto con alguna librería existente.
El análisis de los datos
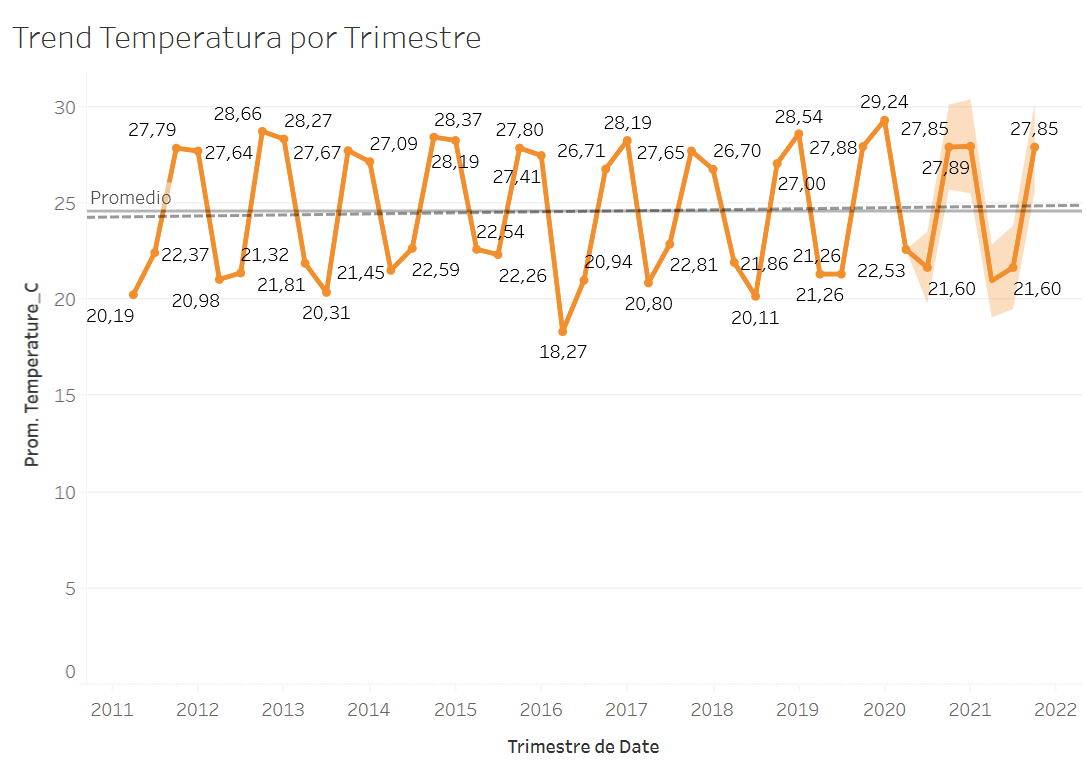
Una vez obtenidos, los datos son almacenados con el formato CSV. Este formato es muy popular en data science y se puede importar rápidamente en todo tiempo de herramientas. Las herramientas que más suelo usar para analizar datos son RStudio, Tableau y PowerBI. Esta vez usé Tableau para analizar los datos de estaciones meteorológicas locales de Filadelfia. Comparto algunos resultados a continuación.
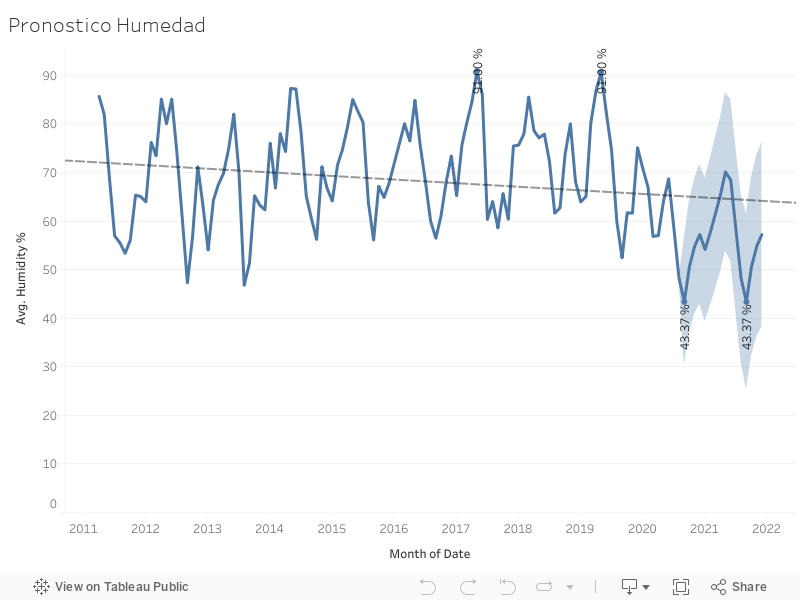
En la imagen se observa un trend fuertemente descendiente de la humedad desde el 2011.
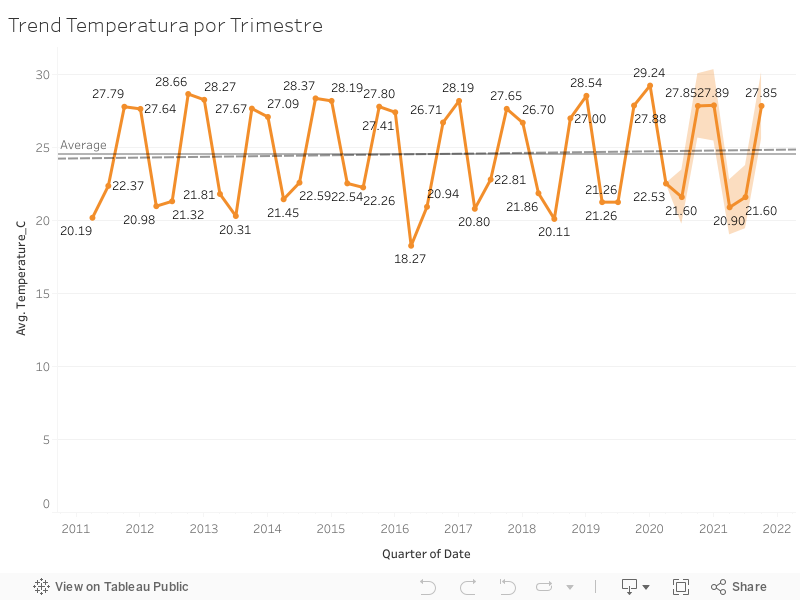
Para ver la galería completa de charts, puedes entrar aquí.
Este análisis generó respuestas muy interesantes en el hilo de twitter. Por ejemplo aprendí que existe el South America low level jet y que su cambio fue causado por la masiva deforestación. Aquí un tweet explicando lo que es.
Cómo crear un proyecto open-source ‘exitoso’
No me considero experto pero aprendí unas cuantas cosas en este y otros proyectos personales y quiero compartirlas, para motivarles a publicar sus propios proyectos open-source.
Quiero aclarar que un proyecto “exitoso” es relativo. Sostengo que cualquier proyecto que publiquen ya es un éxito personal porque sí o sí aprenderán algo en el proceso. Pero hay algunos factores que si los tienen en cuenta, harán más atractivo y fácil de usar al proyecto para otras personas.
El factor más importante para mí es la facilidad con la cuál otras personas pueden empezar a utilizar o aportar al proyecto. Para que sea fácil, el proyecto debe tener un README conciso, y fácil de comprender. Nadie quiere leerse un manual completo para empezar a jugar con código. Mientras con más brevedad puedas lograr que alguien empiece a ejecutar tu código, mejor.
También hay otro factor que es la arquitectura del código. Si quieres que otras personas lean y aporten a tu código, es un gran plus si tu código esta bien estructurado y comentado.
Marketing. Luego de terminar tu repositorio aún queda un paso muy importante. Si el mundo no sabe de tu solución, por más buena que esté, la gente no lo usará. Es crucial que hagas publiques lo que hiciste por más que muchas veces no nos gusta hacer porque parece auto-publicidad.
Si sabes que a otras personas les hará la vida más fácil, va a ser más fácil contarles de tu proyecto. Yo empecé con mis redes sociales y reddit. En cada subreddit hay un reglamento que debes leer antes de publicar tu propio proyecto pero la mayoría dejan que publiques algo personal si es de utilidad para los demás.
Yo cuando publiqué, me sorprendí que en medio día estaba en la cima de r/datasets. En las próximas semanas luego de publicarlo recibí varios mensajes en diferentes medio agradeciéndome por haber creado el scraper. Fue super satisfactoria esta experiencia y hasta ahora me trae nuevas oportunidades, por ejemplo esta post, o trabajos nuevos. Muchas empresas le dan mucha consideración al perfil de Github y justo en estos días otra oportunidad de una empresa grande internacional me vino gracias a este scraper y estoy muy agradecido por ello.